In this article, we will discuss the Grouped Query Attention. We will start with the introduction of the Grouped Query Attention, then we will discuss the limitations of Multi-Head Attention (MHA) and Multi-Query Attention (MQA), and why we need a Grouped Query Attention. We will also discuss the limitations of the Grouped Query Attention and how to implement GQA in the PyTorch library.
Introduction
Grouped Query Attention (GQA) is the attention mechanism introduced in the GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints paper which is a generalization of the Multi-Head Attention (MHA) and Multi-Query Attention (MQA) which uses an intermediate (more than one, less than number of query heads or attention heads) number of key-value heads and achieves quality close to multi-head attention with comparable speed to multi-query attention. GQA is not applied to the encoder self-attention layers because the encoder representations are computed in parallel and the memory bandwith overhead is not a bottleneck.
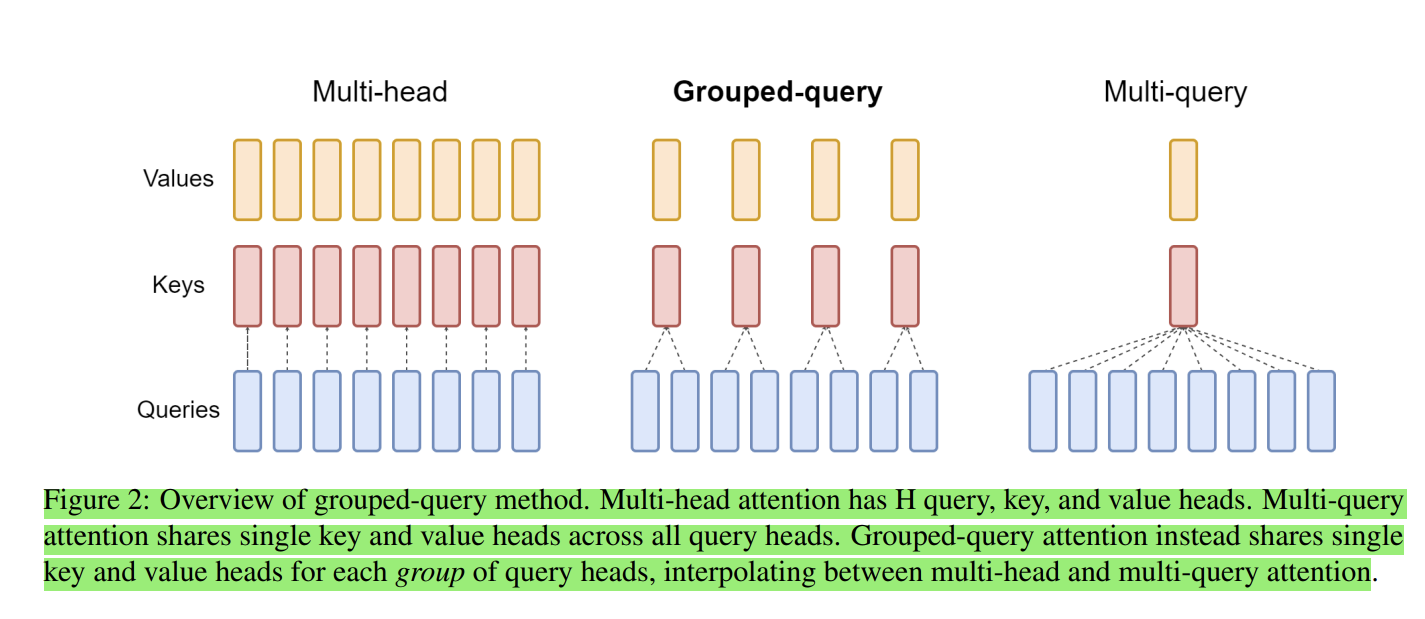
Figure 1 taken from GQA paper.
As shown in the figure, the MHA has H query, key and value heads. MQA shares single key and value across all query heads and GQA shares single key and value heads for each group of query heads. So, GQA is a generalization of MHA and MQA.
What are the limitations of MHA and MQA?
In the Transformer model with KV cache, the autoregressive decoder inference is the bottleneck because of memory bandwith overhead for loading all the attention keys and values at every decoding step. The matrix multiplication for the computation of attention is fast but the data transfer between the memory and the processor is slow. So, the multi-head attention (MHA) with KV cache is not efficient for autoregressive decoding since the memory access of all the keys and values is required at every decoding step which is slow.
On the other hand, the multi-query attention (MQA) uses a single key and value heads for all the query heads which sharply reduces the H dimension from key and value heads to 1. This reduces the memory bandwith overhead for loading the attention keys and values at every decoding step but it leads to quality degradation and training instability.
Large Language Models (LLMs) generally scale the number of heads, such that multi-query attention (MQA) represents a more aggressive cut in both memory bandwith and quality. So, there is a need for Grouped Query Attention that can achieve quality close to multi-head attention with comparable speed to multi-query attention.
Why do we need a Grouped Query Attention?
Grouped Query Attention (GQA) divides the query heads into groups and shares the key and value heads for each group in such a way to generate the interpolated model of multi-head and multi-query attention that achieves quality close to multi-head attention with comparable speed to multi-query attention. So, we need a Grouped Query Attention.
How to implement a Grouped Query Attention?
While working on the implementation of the Llama 2: Open Foundation and Fine-Tuned Chat Models, I implemented the Grouped Query Attention.
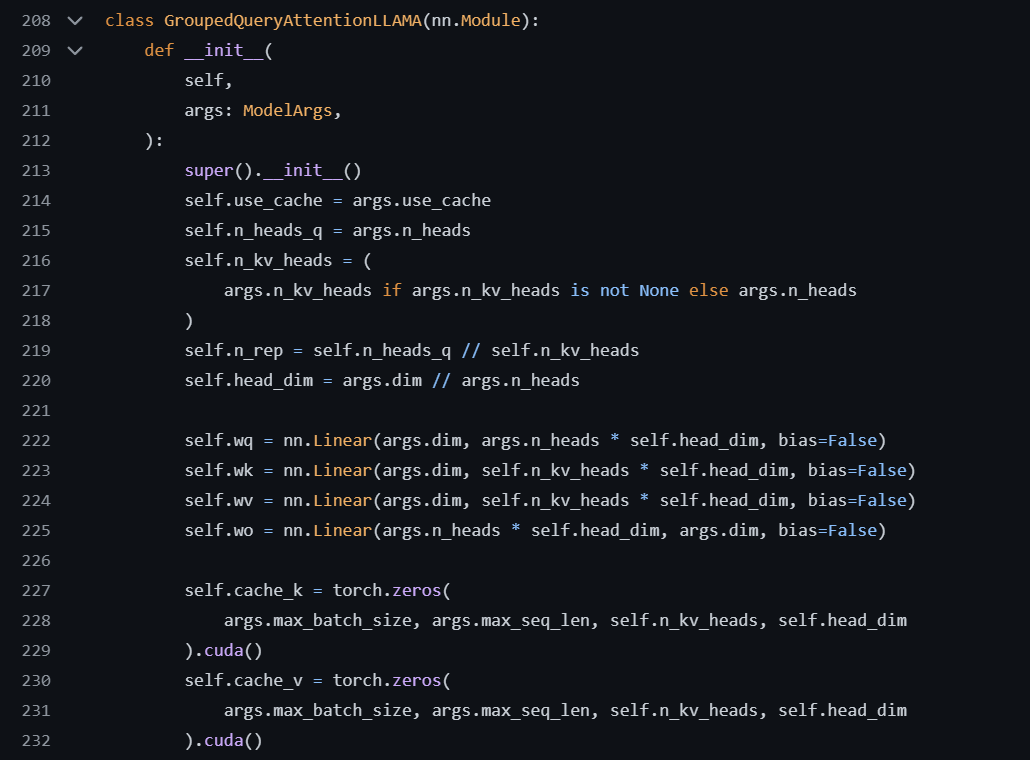
Figure 2 presents the constructor of GQA.
The constructor of GQA is shown in the figure 2. The constructor of GQA initializes the number of query heads, key and value heads, and the 3 parameterized matrices which are trainable.
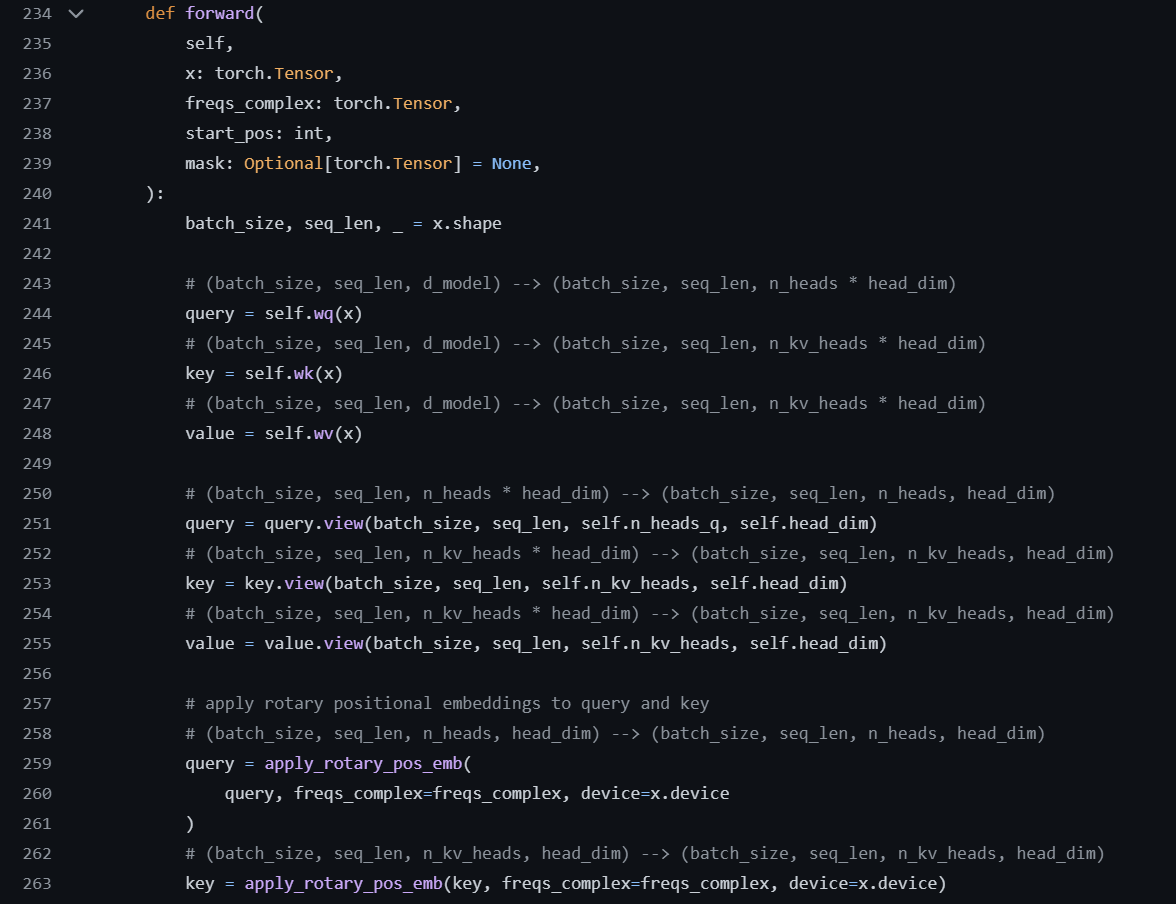
Figure 2 presents the first part of GQA.
In the forward method of GQA, the query, key and value are multiplied with the parameterized matrices and then we are applying the Rotary Positional Embedding to the query and key. You can learn more about the Rotary Positional Embedding from my article LLAMA: OPEN AND EFFICIENT LLM NOTES. Basically, the Rotary Positional Embedding uses a rotation matrix to encode the positional encoding to the attention rather than adding the positional encoding vectors to the query and key as done in Relative Positional Embedding which resolves the essence of extra computation.
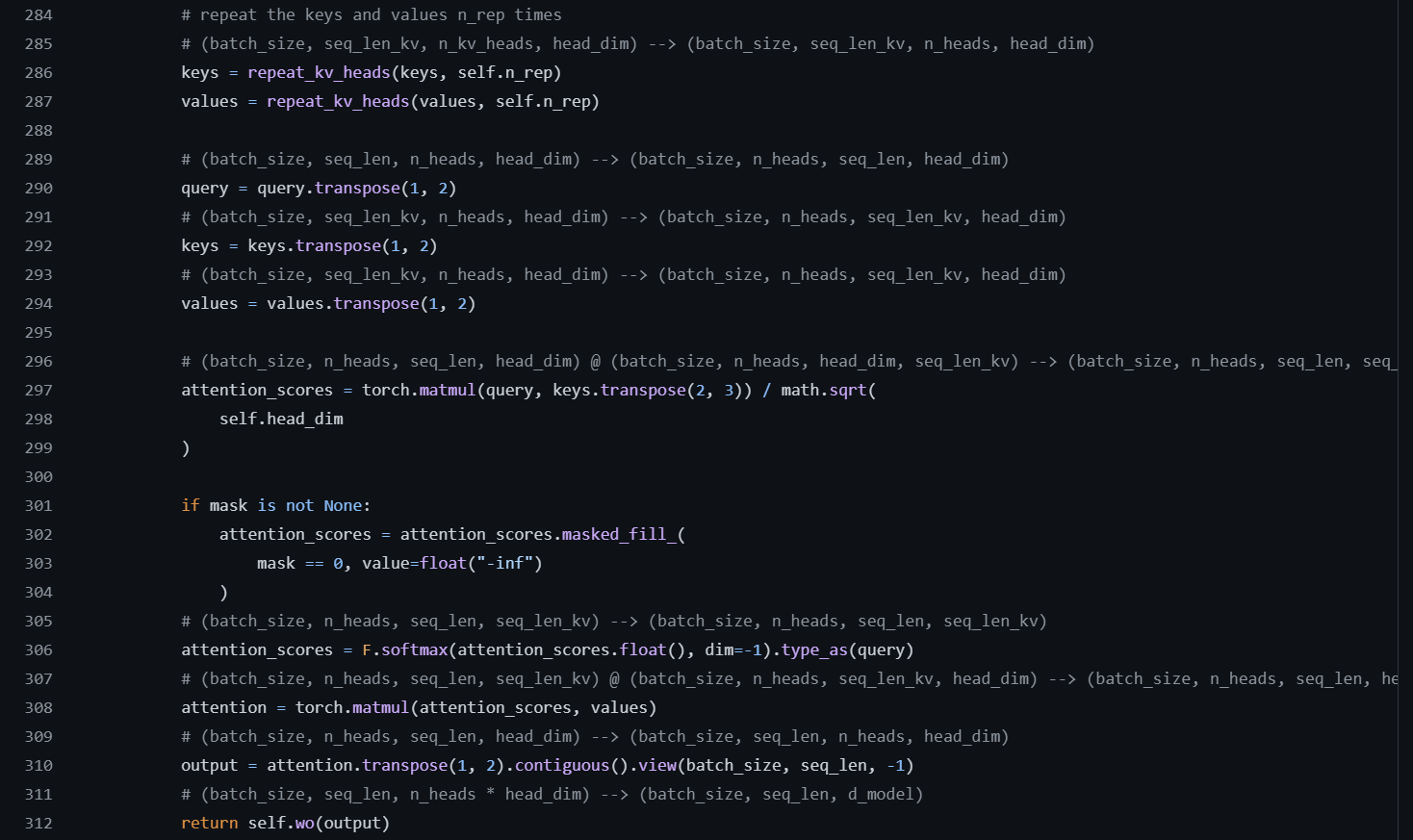
Figure 3 presents the last part of GQA.
In the last part of the forward method of GQA as shown in the figure 3, the key and value are repeated for the number of query heads and then the query, key and value are used to compute the attention. I have removed the KV cache from the above code for simplicity but you can see the detailed implementation of enabling and disabling the KV cache in my Llama 2 implementation here.
Conclusion
So, Grouped Query Attention is an interpolation of multi-head attention and multi-query attention that achieves quality close to multi-head attention with comparable speed to multi-query attention. In this article, we discussed the Grouped Query Attention. We started with the introduction of the Grouped Query Attention, then we discussed the limitations of Multi-Head Attention and Multi-Query Attention, and why we need a Grouped Query Attention. We also see the implementation of GQA in the PyTorch library. You can also check my implementation of Llama 2 here.